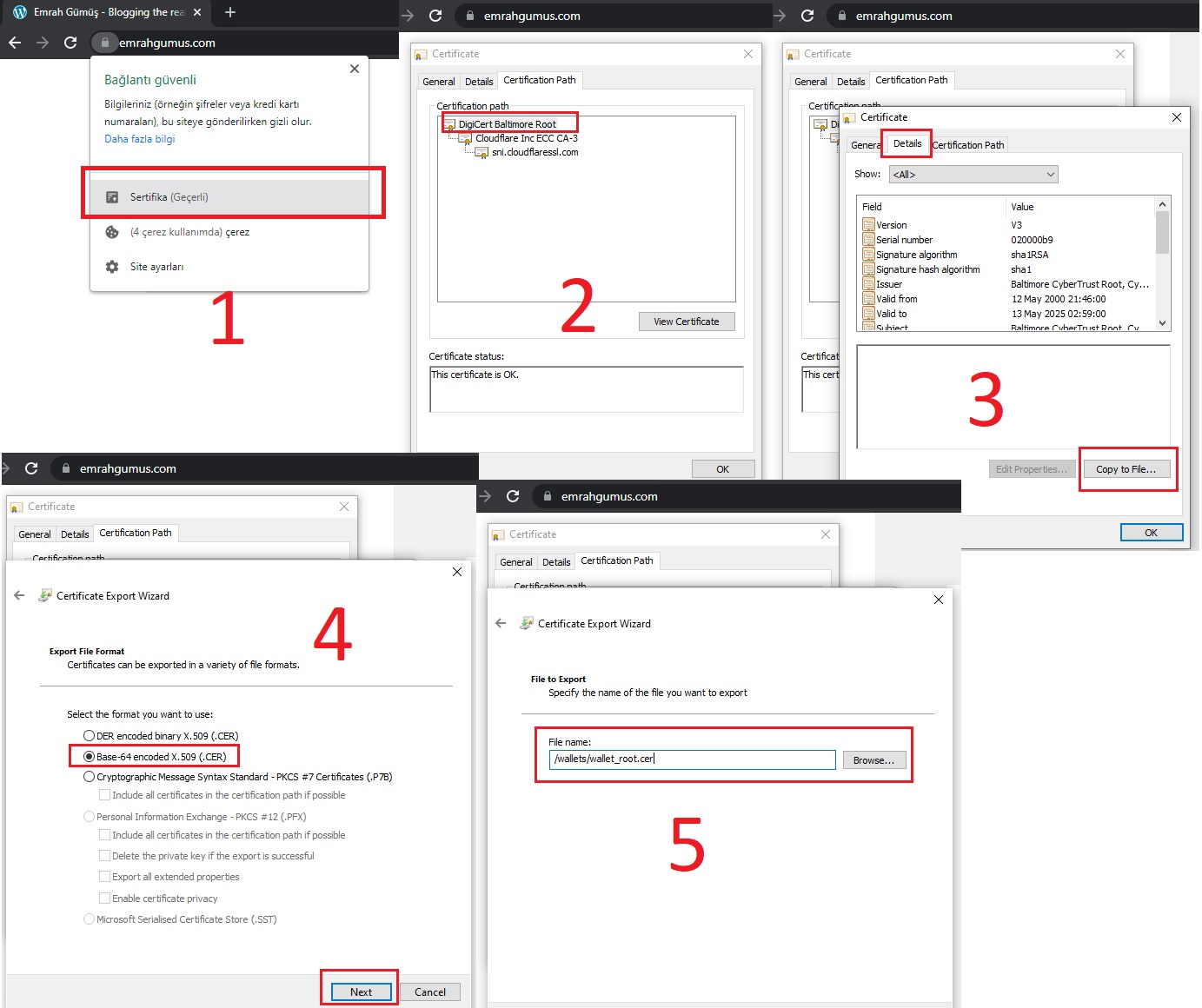
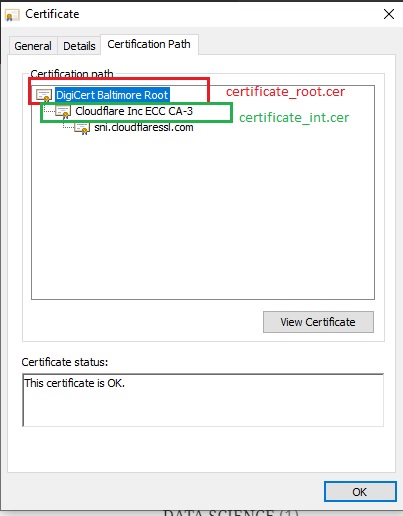
Download certificates to your computer as below (certificate_root and certificate_int)
Create an wallet via orapki
orapki wallet create -wallet <wallet_location> -pwd <password> -auto_login
Then add certificates into wallet.
orapki wallet add -wallet <wallet_location> -trusted_cert -cert "<wallet_location>/certificate_root.cer" -pwd <password>
orapki wallet add -wallet <wallet_location> -trusted_cert -cert "<wallet_location>/certificate_int.cer" -pwd <password>
Show ACLs
SQL> SELECT * FROM dba_network_acls ORDER BY acl; SQL> SELECT * FROM dba_network_acl_privileges ORDER BY acl, aclid, privilege;
Create an ACL from database and assign site address.
BEGIN SYS.dbms_network_acl_admin.create_acl( acl => '<ACL_NAME>', description => '<ACL DESCRIPTION>', principal => '<ORACLE_USER>', is_grant => TRUE, privilege => 'connect', start_date => null, end_date => null ); SYS.DBMS_NETWORK_ACL_ADMIN.ADD_PRIVILEGE( acl => '<ACL_NAME>', principal => '<ORACLE_USER>', is_grant => true, privilege => 'connect' ); SYS.DBMS_NETWORK_ACL_ADMIN.ADD_PRIVILEGE( acl => '<ACL_NAME>', principal => '<ORACLE_USER>', is_grant => true, privilege => 'resolve' ); SYS.dbms_network_acl_admin.assign_acl( acl => '<ACL_NAME>', host => '*.emrahgumus.com', lower_port => null, upper_port => null ); END; /
Then you can test via below code.
SET SERVEROUTPUT ON SIZE UNLIMITED;
DECLARE
lo_req UTL_HTTP.req;
lo_resp UTL_HTTP.resp;
BEGIN
UTL_HTTP.SET_WALLET (
'file:<wallet_location>',
'<password>');
lo_req := UTL_HTTP.begin_request ('https://www.emrahgumus.com');
lo_resp := UTL_HTTP.get_response (lo_req);
DBMS_OUTPUT.put_line (lo_resp.status_code);
UTL_HTTP.end_response (lo_resp);
END;
/